

Quantum-CLI: A powerful CLI to build, run, and test Quantum Machines.

Execute Your Workflow in a Loop with QuantumDataLytica
QuantumLoop is a powerful enhancement to our no-code data automation platform.

QuantumDataLytica vs Traditional ETL Tools: Accelerate Your Data Integration Without Coding
Traditional Extract, Transform, Load (ETL) tools have long been at the core of data integration practices.
QuantumDataLytica: The No-Code Alternative to Traditional ETL
For years, ETL (Extract, Transform, Load) solutions have been the cornerstone of data integration.
A no-code data engineering platform, proven in production.
How one mid-market operator replaced its entire data engineering function with automated pipelines on QuantumDataLytica — and what it proves for every data-driven industry.
Table of Contents
RevEVOLVE needed clean data, on tap
Hotel Switchboard LLC operates RevEVOLVE, an AI-powered revenue management system for multi-property operators. Its forecasting, dynamic pricing, and RM copilot are only as good as the data behind them.
That data lives in a dozen disconnected systems — property management systems, channel managers, OTAs, and rate-shopping tools — each with its own format, login, and quirks. It’s the defining problem of every data-aggregation business, not just hotels.
The pipelines are never done
Every company that turns fragmented source data into a product falls into the same trap. Sources change, formats drift, logins expire — and a small engineering team ends up spending most of its time maintaining brittle custom connectors instead of building the product customers actually pay for. Data engineering becomes a cost center that scales linearly with every new source, property, and client.
One marketplace, the whole workflow
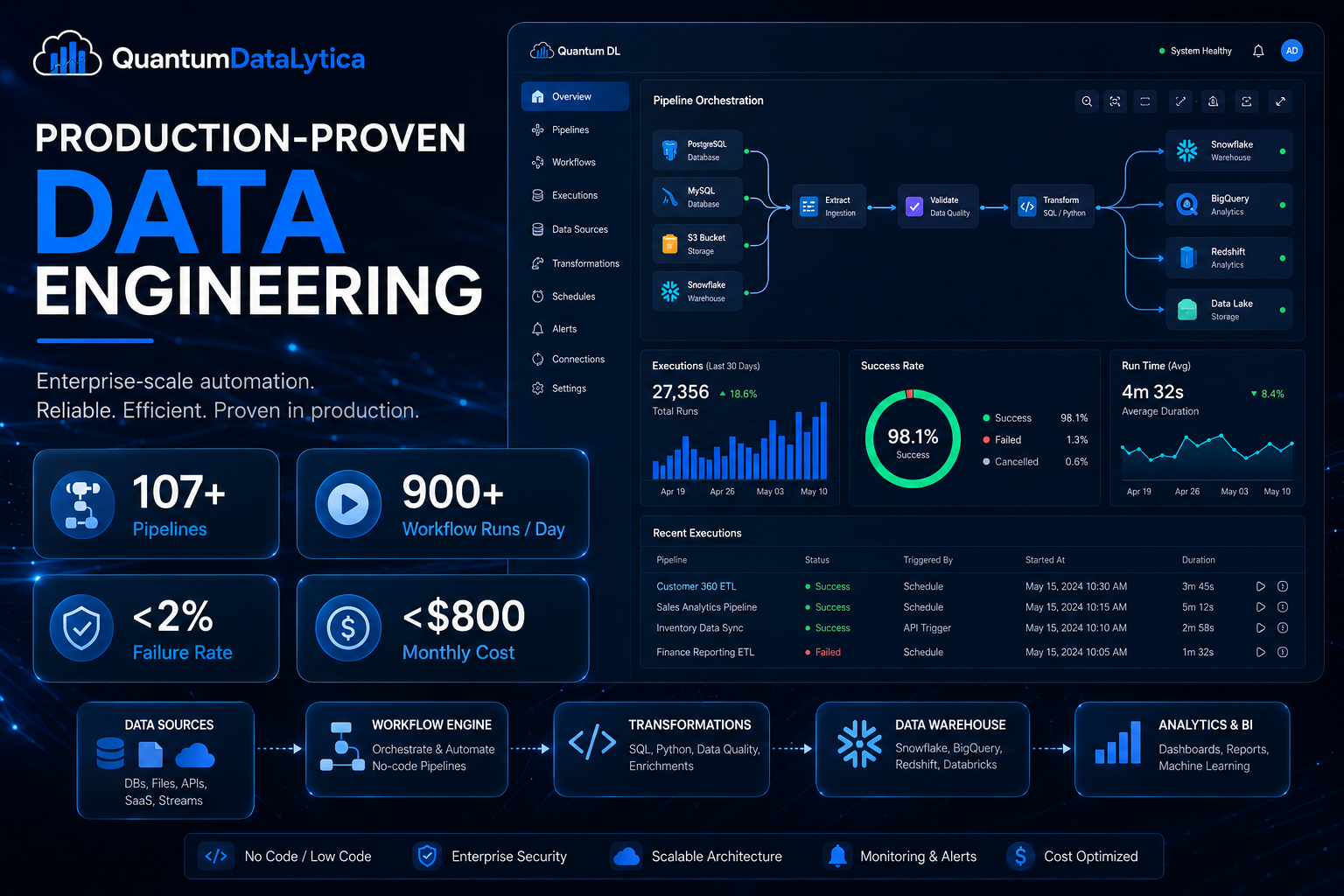
Hotel Switchboard rebuilt its entire data backbone on QuantumDataLytica’s machine marketplace — assembling 138 pipelines from pre-built, reusable components instead of writing code from scratch. The workflows span the full lifecycle:
Ingestion
Secure connectors pull reservation, occupancy, and rate data from multiple PMS platforms — Choice, OperaCloud, and RmsCloud — plus competitive rate intelligence via RateShop Lighthouse.
Standardization & storage
Raw, inconsistent exports are normalized into a unified schema automatically, then persisted and backed up across the property estate — before anything reaches the intelligence layer.
Orchestration
Pipelines are chained and scheduled to run multiple times per day, with loop logic for parallel property processing and zero manual intervention. QuantumDataLytica became the nervous system; RevEVOLVE just consumes clean, current data on tap.
Enterprise-scale data engineering, on a startup budget

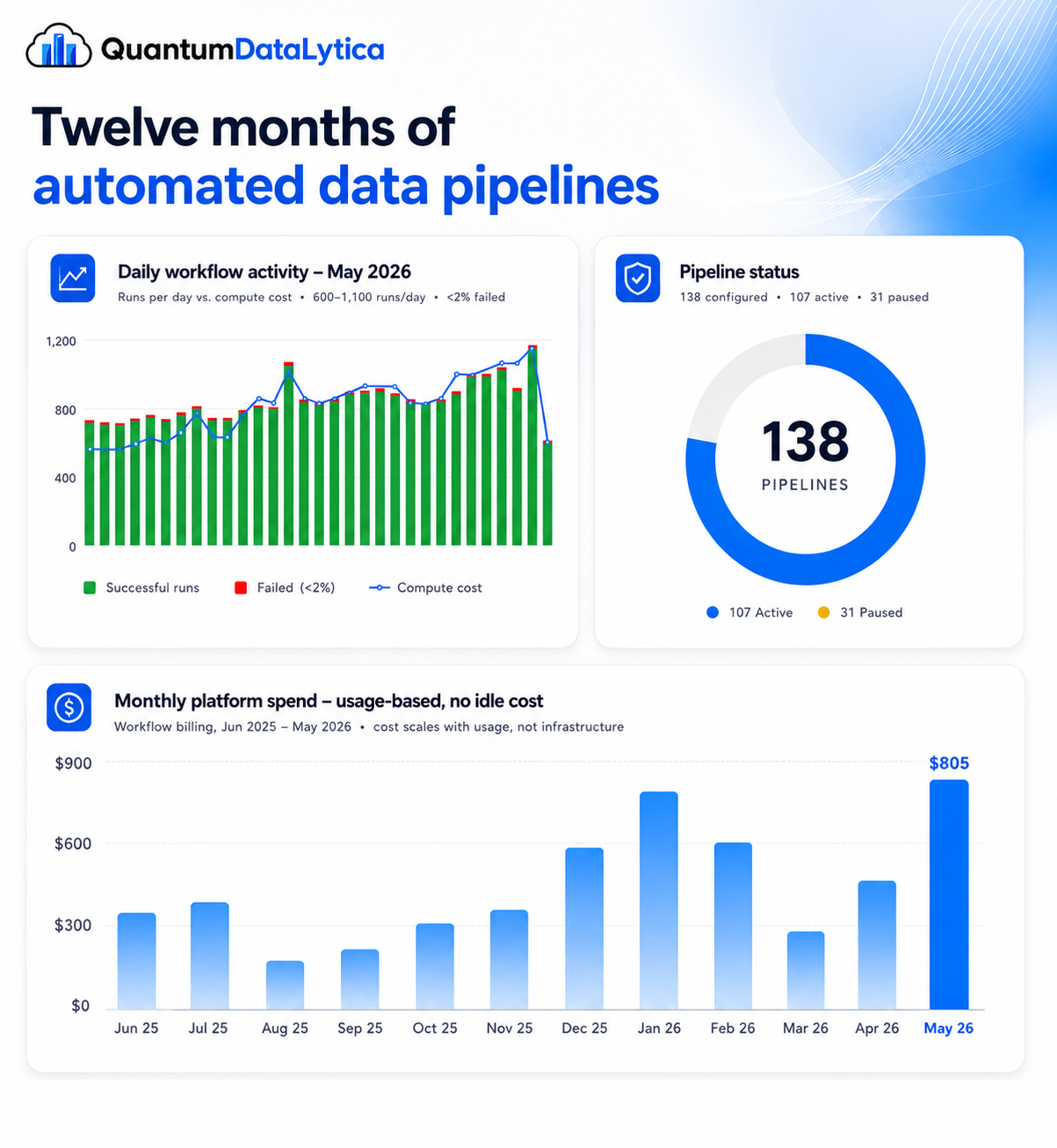
After roughly twelve months in production, the numbers speak for themselves: 107 active pipelines, 900+ executions on a typical day with peaks near 1,180, and a sustained failure rate under 2% — all unattended. All-in platform spend peaks under $800/month and averages well under $500, on the order of a few cents per workflow run. Because the architecture is serverless, spend rose with usage (up ~84% in the latest month) and the platform absorbed it with no provisioning, no scaling project, and no surprise bill. Nothing sits idle; cost tracks value.
The same blueprint runs in any data-driven industry
Strip away the hotel terminology and the pattern is universal: ingest from fragmented sources, standardize, store, orchestrate, repeat. The primitives don’t change — only the connectors do.
| INDUSTRY | FRAGMENTED SOURCES TO UNIFY | WHAT QUANTUMDATALYTICA DELIVERS |
|---|---|---|
|
Hospitality proven in this case study |
PMS, channel managers, OTAs, rate shopping | Automated revenue-management data pipelines |
| Healthcare | EHRs, claims, scheduling systems | Compliant healthcare data integration |
| Retail & e-commerce | POS, loyalty, marketplace feeds | Unified commerce data aggregation |
| Sports & golf | Tee sheets, booking, membership | No-code analytics data pipelines |
| Finance | Core banking, market & reference data | Automated ETL for financial data |
A mid-market operator with no data engineering team now runs enterprise-scale data operations for the cost of a single software seat. Any agency or platform aggregating data across messy sources can do the same. This isn’t a connector tool or a point solution — it’s a true data engineering platform, proven at scale, in production, every single day.
Data engineering platform FAQ
Q1. What is a no-code data engineering platform?
A no-code data engineering platform lets teams build, run, and orchestrate production data pipelines by assembling pre-built components instead of writing custom code. On QuantumDataLytica, you drag and drop from a marketplace of 130+ reusable “machines” for ingestion, standardization, storage, AI inference, and orchestration, then schedule them to run automatically.
Q2. How much does data pipeline automation cost?
Pricing is serverless and usage-based, so cost tracks actual workflow runs with no idle infrastructure charges. In this case study, a multi-property operator runs 138 configured pipelines with 900+ executions per day for a peak monthly cost under $800 — a fraction of the cost of an in-house data engineering team.
Q3. Can no-code data pipelines run at production scale?
Yes. This case study documents 107 active pipelines in continuous production for roughly 12 months, processing 900+ workflow runs on a typical day and peaking near 1,180, with a sustained failure rate under 2% and no manual intervention.
Q4. Is QuantumDataLytica an alternative to Fivetran, Airbyte, or dbt?
QuantumDataLytica covers the full data workflow — ingestion, standardization, storage, AI inference, and orchestration — in one no-code platform. Fivetran and Airbyte focus on connectors and dbt focuses on transformation; QuantumDataLytica unifies the entire pipeline as a marketplace of reusable components, making it an alternative for teams that want end-to-end automation rather than stitched-together point solutions.
Q5. Which industries use QuantumDataLytica for data integration?
The platform is industry-agnostic. The pattern proven in hospitality applies directly to healthcare (EHRs and claims), retail (POS and loyalty), sports and golf (booking and membership), and finance (core banking and market data).
Recent Use Cases
-
02 Jun, 2026
A no-code data engineering platform, proven in production.
-
01 Dec, 2025
How Hotel Switchboard Cut Cloud Costs by 51% and Scaled to 500+ Properties Using QuantumDataLytica
-
27 Aug, 2025
How We Helped a Healthcare Digital Marketing Firm Automate 10K+ Social Posts With 99.99% Success & 75% Cost Reduction
-
09 Apr, 2025
How Exitofresh Supermarket Accelerated Operational Efficiency with QuantumDataLytica
-
09 Feb, 2025
Automating Hotel Rate Shopping with QuantumDataLytica
Testimonial
We replaced a constant engineering fire drill with a system that just runs. Our team builds product now instead of babysitting pipelines.
— Jigar Patel CEO @ Hotel Switchboard LLC, IL, USAYour team shouldn't rebuild the same pipelines every quarter.
You're paying engineering salaries to do what a marketplace does for cents. See QuantumDataLytica run your data workflow end to end. Book a demo
